Not long ago, we presented DHTMLX MCP Server – a unified source of knowledge that allows AI assistants and dev tools structured access to up-to-date documentation for all our products, from any Suite widget to Gantt and Scheduler. To achieve this goal, we had to find a solution for a non-trivial engineering task: extend a knowledge system designed for a single product to an entire ecosystem.
At the core of our MCP server lies the Retrieval-Augmented Generation (RAG) architecture, which retrieves relevant pieces of data from the documentation and feeds them to LLMs to generate accurate answers. It works well for a single product, but things get complicated when it is necessary to service an entire ecosystem.
RAG and MCP Basics
First, let us establish the groundwork and go through the core principles of RAG and MCP.
How do you build a RAG (Retrieval-Augmented Generation) solution and expose it as an MCP (Model Context Protocol) Server?
RAG is an approach to enriching an LLM’s context, consisting of three phases:
- Retrieval – fetch relevant external knowledge
- Augmentation – inject context into prompt
- Generation – produce an answer with context
The pipeline is straightforward: you load your documents, turn each chunk of text into a numerical vector (an embedding), store those vectors in a searchable database (an index), and then use a similarity metric (such as cosine similarity) to retrieve the chunks that are closest in meaning to the user’s query.
Model Context Protocol (MCP) can be referred to as a “USB-C” connector for AI apps. It provides a standardized way for AI agents to access external systems via:
- Tools – API calls, database queries
- Resources – documentation pages, agentic skills
- Prompts – common workflows, few-shot samples
In some sense, MCP transforms an LLM from a static source of knowledge into a system capable of understanding dynamic environmental knowledge.
Here comes a natural question: what do you need to build such a smart system? MCP servers with RAG capabilities are commonly built using special frameworks. Here are the most options:
- FastMCP is considered to be a standard choice for building the MCP layer
- LlamaIndex is perfect for heavy knowledge-oriented RAG
- LangChain focuses more on agent-oriented workflows
Many people believe that such solutions are developed in Python, but this is a misconception. Both LlamaIndex and LangChain allow you to build solutions in JavaScript, and MCP is a protocol that can have a wide variety of SDKs for different languages.
At first glance, the path seems straightforward: choose the right tools and assemble an RAG-MCP stack for your project. The real challenge occurs when the same system needs to support multiple products with distinct documentation and APIs. This forces you to rethink how the knowledge base should be structured.
Way to Machine Learning
The first instinct when scaling your RAG system might be to create a single, unified index for all products. From an infrastructure perspective, it seems logical, but in practice, it leads to considerable performance degradation.
DHTMLX JavaScript UI components have distinct internal logic. When you mix knowledge about Gantt and Scheduler in the same vector space, domain interference occurs. The system starts confusing API methods, suggesting functions from one product to solve problems in another. Quality drops, and users receive irrelevant recommendations.
The solution seemed obvious: isolate the knowledge. We created a separate index for each product. This solved the accuracy problem within specific domains but introduced a new engineering challenge: how do we know which index contains knowledge for a given user query?
But at this stage, we faced a routing problem. We needed to direct the user’s query to the correct product index before the retrieval phase could even begin. From the developer’s viewpoint, it seemed reasonable to use classical solutions: keyword matching, regular expressions, fuzzy matching, or even calling a full-scale LLM for intent classification. But, in practice, these approaches have significant limitations:
- Heuristic approaches (keywords, regex, fuzzy rules) are too unreliable because users’ queries are random.
- LLM routing works, but it is slow and doesn’t fit our high-load system.
We needed both – the speed of hardcoded rules and the flexibility of LLMs. That led us to create a custom ML model specifically for domain classification.
Machine Learning Breakthrough
For this task, it was necessary to find the optimal price-to-performance ratio. We needed a model that processes requests in milliseconds without requiring massive computational resources.
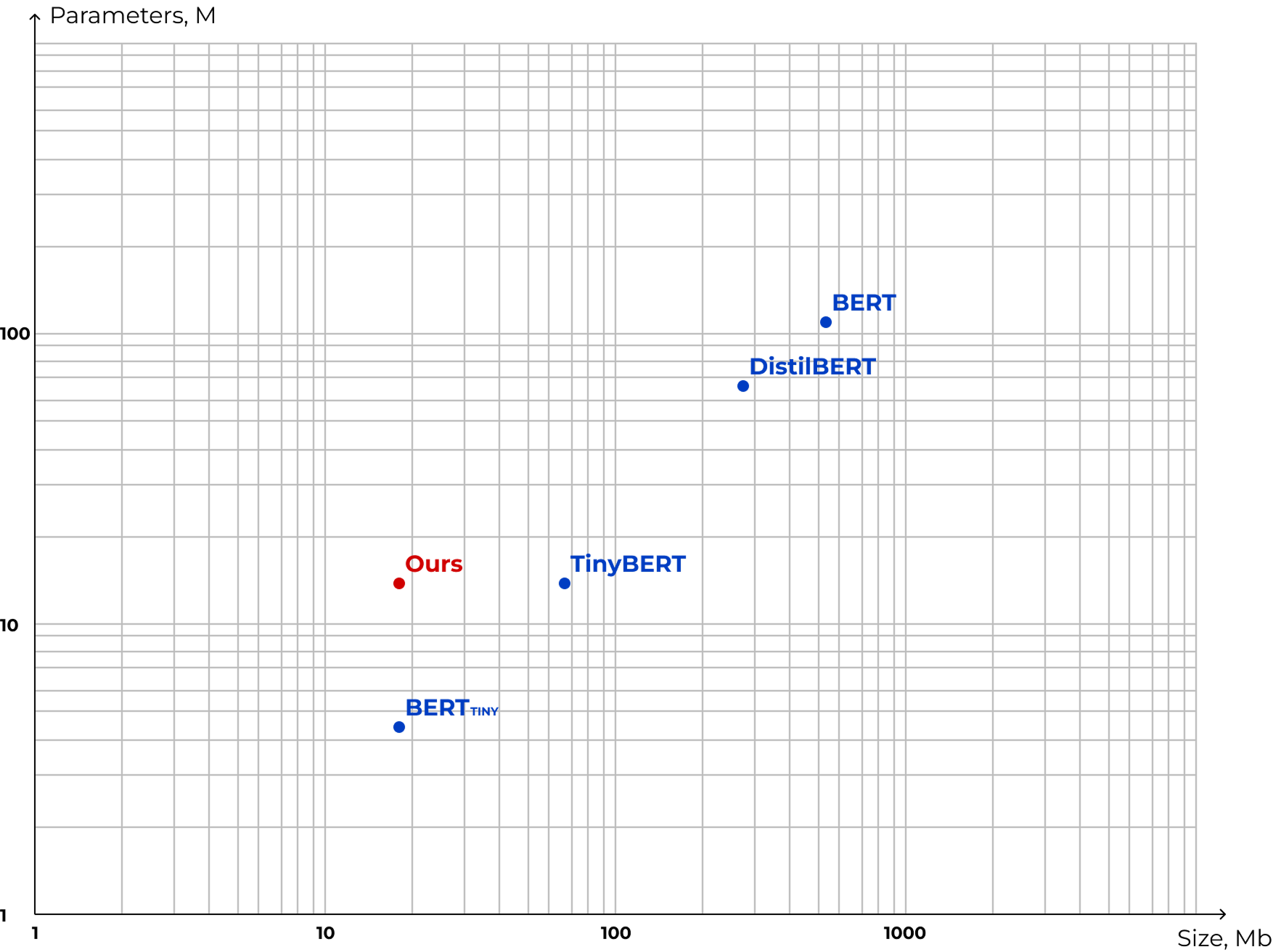
We visualized our requirements on a graph with two axes:
- Parameters – units capable of storing information; more parameters generally imply a “smarter” model.
- Size – the memory footprint; a smaller size means faster inference and lower server load.
Our goal was to find a balance: maximum parameters with minimum memory usage, while also preserving the quality. As the graph shows, we managed to reach the desired result!
So, how do you create a model that fits in a few megabytes but understands documentation nuances better than giants like BERT? We applied two key machine learning techniques: distillation and quantization.
Distillation is the process of a “student-teacher” interaction. Here, the massive pre-trained model (teacher), which excels at context understanding, is used to train a lightweight model (student). A “student” here learns to mimic the teacher’s answers, absorbing the knowledge while shedding the heavy weights. This technique allows for preserving the quality of understanding for complex technical queries.
Quantization is the way of reducing a model’s size while preserving the amount of trainable parameters. Typically, model parameters are stored in 32-bit format; there are plenty of techniques to reduce them down to 1.58-bit. In our case, we chose 8-bit formatting.
As a result, our model sits outside the standard pattern: it possesses knowledge comparable to TinyBERT but occupies a size similar to BERT_TINY. And, most importantly, this solution provides acceptable accuracy with optimal resource consumption.
Wrapping Up
Scaling our knowledge system wasn’t just about adding more data but rather about rethinking how that data was organized and accessed. What initially seemed like obvious architectural choices caused more confusion, and standard web development tools just couldn’t keep up with the unpredictability of user questions.
Introducing a custom machine learning model helped us to strike the right balance. It provides the speed required for heavy loads and understands the nuances of the DHTMLX documentation. So, if you plan to use AI assistants in implementing enterprise-grade apps with DHTMLX, adding the DHTMLX MCP server will help AI tools get access to the latest documentation versions and avoid confusion during the development cycle.